MultiThreading & MultiProcess
Thread 란?
- CPU 사용의 아주 작은 단위
- OS 시스템이 발달하기 전에는 연산이 병목이였다면 현재는 I/O가 병목이므로 thread의 비용 개선의 역할이 커졌다.
그렇다면 Multi-Processing과 Multi-Thread의 방식의 차이점은 무엇일까?
프로세스를 죽이고 살리는데 오버헤드가 크다는 단점이 존재한다. Code data, data section(RAM)을 메모리에 복사하여 메모리에 올리게 된다. 우리는 하나의 프로그램 안에서 연산이 된다고 생각하지만 실질적으로는 우리가 multi processing working의 개수만큼 프로그램을 더 띄우는 것이라고 생각하면 된다. 이렇게 생각하면 우리가 생각하는 것보다 얼마나 오버헤드가 많이 일어나는 것을 짐작해 볼 수 있을 것이다.
멀티 스레딩(multithrading)?

- 데이터 섹션은 공유한다.
- 스레딩 방식에는 여러 방식이 존재한다.
Many-to-one-model
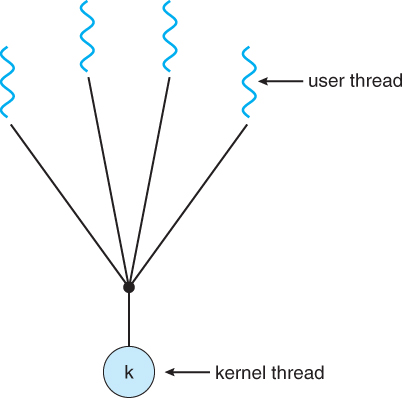
- 하나의 커널이 여러 스레드를 처리하는 방식이다.
- 하나의 커널이 처리하기 때문에 한 스레드가 lock이 걸리게 된다면 다른 thread의 처리도 멈춘다는 단점이 존재한다.
One-to-one-model
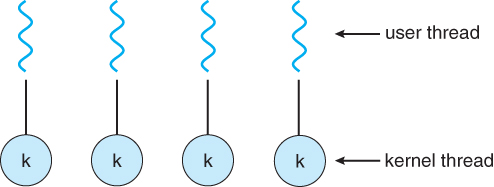
- 하나의 커널이 하나의 스레드를 처리하지만, 여러 커널이 존재하는 경우이다.
- 각 커널이 한 thread를 담당하기 때문에 일의 처리를 조금 더 빨리 할 순 있지만 많은 코어가 필요가 필요하기 때문에 비용 측면에서의 단점이 존재한다.
Many-to-many-model

- 여러 커널이 여러 thread를 처리하는 방식으로 동시에 연산이 가능해 효율적인 단점이 있지만 너무 많은 thread를 펼 경우 오히려 속도 절감을 낳을 수 있다.
Python에서 Thread 사용하기
import threading
import queue
import requests
import time
# 일거리들
urls = [
'http://www.google.com',
'http://www.facebook.com/',
'http://www.daum.net/',
'http://www.github.com/',
'http://flyasiana.com/',
'http://www.naver.com',
'http://www.youtube.com',
'http://www.facebook.com/',
'http://www.daum.net/',
'http://www.github.com/',
'http://flyasiana.com/',
'http://www.github.com/',
'http://flyasiana.com/',
'http://www.naver.com',
'http://www.youtube.com',
'http://www.facebook.com/',
'http://www.naver.com',
'http://www.youtube.com',
'http://www.facebook.com/',
'http://www.daum.net/',
'http://www.github.com/',
]
# 할일을 담는 큐를 만들어준다. 이 친구들은 스레드끼리
# 서로 순서가 엉키거나 동시에 처리되지 않게
# 데이터를 관리하는 역할을 한다.
jobs = queue.Queue() # thread-safe
results = queue.Queue() # thread-safe
# 각 스레드가 실행할 함수. 스레드는 이 함수를 실행하기 위해 생성되고, 함수가 리턴되면 스레드도 죽는다.
# 스레드는 이 함수를 위해 살고 죽는다.
def run_task(job_queue, result_queue):
# 무한루프를 도는 이유는 한 스레드가 job queue에서 지속적으로
# 할일을 가져와서 계속 일을 해야 하기 때문이다.
while True:
# 할일 가져와
url = job_queue.get()
if url is None: # '멈춰' 라는 신호를 받은 경우 ("stopper")
print('Thread 죽습니다')
break
######## 각 스레드가 어떤 일을 할지 정의된 구간 ########
print('doing work for: {}'.format(url))
# 할것 하고 - 여기가 병목인 코드(IO-bound)가 수행되는 지점입니다.
res = requests.get(url)
# 결과를 insert
result_queue.put(res.text)
######## 각 스레드가 어떤 일을 할지 정의된 구간 (끝) ########
# 생성할 스레드 개수
num_threads = 4
# 스레드를 생성한다. 그런데 여기서 스레드가 생기기만 하고
# run_task가 실제로 돌고 있지는 않는다.
workers = [
threading.Thread(target=run_task, args=(jobs, results))
for _ in range(num_threads)]
# 너네 일 시작해 - 여기서 run_task가 실행된다.
# 이 시점에는 아직 job_queue 안에 아무것도 안 들어있기 때문에
# 각 스레드의 run_task는 job_queue.get() 이 호출되는 line에서 멈춰있게 된다.
# 여기서부터는 스레드가 정말로 여러개가 동시에 돌아가기 시작하는 지점이다.
for worker in workers:
worker.start()
print('Running for total {} urls'.format(len(urls)))
# 일거리를 넣어준다.
# queue에 일거리가 들어가면 스레드들이 하나씩 뽑아가서 일을 수행한다.
start_time = time.time()
for url in urls:
jobs.put(url)
# 멈추라는 신호(= 할일이 끝났다는 신호)를 준다. (== None)
# 스레드마다 하나씩 멈추라는 신호를 받아야 하므로 스레드 개수만큼 넣어준다.
for _ in range(num_threads):
jobs.put(None)
# 스레드들이 일을 다 할때까지 엄마가 기다려
# 여기서부터 엄마는 스레드들이 전부 종료될때까지 기다린다.
# 기다리는 동안 스레드들은 각자 동시에 일을 수행한다.
for worker in workers:
worker.join()
print('끝났다!')
end_time = time.time()
print('Elapsed: {}'.format(end_time - start_tim
위처럼 회사 업무중 timeout error나는 작업을 개선할 기회가 있었는데 작업 처리 시간이 대략 1/7로 줄어들었다!
Thread에서 중요하게 생각해야 할 것이 있다. 그것은 Data section을 공유하기 때문에 어떠한 데이터 구조를 이용할 경우 Thread-safe한 데이터 구조를 활용해야 한다.
Thread-Safe이란?
예를 들어 한 Array List에 작업한 결과를 담아야 한다고 하자. 만약에 Multiprocessing의 경우에는 data section을 공유하지 않기 때문에 각 프로세스에서 그 데이터 구조에 대해 연산 작업을 진행하면 된다. 하지만 Multithreading 경우에는 data section을 공유한다. 내가 생각한 0번 인덱스의 값을 가져와 연산을 해야 하는데 그 전 thread 가 내가 연산 해야할 0번 인덱스를 지우면 어떻게 될까? 꼬인다. 그래서 우리는 multiThreading 방식을 써야할 땐 Thread-safe한 Data Structure을 이용해야 할 것이다. 물론 개발자가 mutex, lock.. 등을 이용해 일일이 코딩해 주어도 되지만 안정성에 대해서는 보장하지 못할 것이다.